- Overview
- Definitions
- Requirements
- Dependencies
- Design Highlights
- Logical Specification
- rmw-degraded-readIO
- rmw-degraded-writeIO
- Conformance
- Unit Tests
- System Tests
- Analysis
- References
Overview
The read-modify-write feature provides support to do partial parity group IO requests on a Motr client. This feature is needed for write IO requests only.
Motr uses notion of layout to represent how file data is spread over multiple objects. Motr client is supposed to work with layout independent code for IO requests. Using layouts, various RAID patterns like RAID5, parity declustered RAID can be supported.
Often, incoming write IO requests do not span whole parity group of file data. In such cases, additional data must be read from the same parity group to have enough information to compute new parity. Then data is changed as per the user request and later sent for write to server. Such actions are taken only for write IO path. Read IO requests do not need any such support.
Definitions
m0t1fs - Motr client file system. layout - A map which decides how to distribute file data over a number of objects.
Requirements
- R.m0t1fs.rmw_io.rmw The implementation shall provide support for partial parity group IO requests.
- R.m0t1fs.fullvectIO The implementation shall support fully vectored scatter-gather IO where multiple IO segments could be directed towards multiple file offsets. This functionality will be used by cluster library writers through an ioctl.
- R.m0t1fs.rmw_io.efficient IO requests should be implemented efficiently. Since Motr follows async nature of APIs as far as possible, the implementation will stick to async APIs and shall avoid blocking calls.
Dependencies
- An async way of waiting for reply rpc item from rpc layer.
- Generic layout code.
Design Highlights
- All IO requests (spanning full or partial parity group) follow same code path.
- For IO requests which span whole parity group/s, IO is issued immediately.
- Read IO requests are issued only for units with at least one single byte of valid file data along with parity units. Ergo, no read IO is done beyond end-of-file.
- In case of partial parity group write IO request, a read request is issued to read necessary data blocks and parity blocks.
- Read requests will be issued to read the data pages which are partially spanned by the incoming IO requests. For write requests, The data pages which are completely spanned will be populated by copying data from user-space buffers.
- Once read is complete, changes are made to partially spanned data buffers (typically these are pages from page cache) and parity is calculated in iterative manner. See the example below.
- And then write requests are dispatched for the changed data blocks and the parity block from parity group/s.
If
Do - Data from older version of data block.
Dn - Data from new version of data block.
Po - Parity for older version of parity group.
Then,
delta - 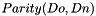 (Difference between 2 versions of data block)
(Difference between 2 versions of data block)
Pn - 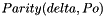 (Parity for new version of parity group)
(Parity for new version of parity group)
Logical Specification
- Component Overview
- Subcomponent design
- Small IO requests
- Subcomponent Data Structures
- Subcomponent Subroutines
- rmwDFSInternal
- State Specification
- Threading and Concurrency Model
- NUMA optimizations
Component Overview
- First, rwm_io component works with generic layout component to retrieve list of data units and parity units for given parity group.
- Then it interacts with rpc bulk API to send IO fops to data server.
- All IO fops are dispatched asynchronously at once and the caller thread sleeps over the condition of all fops getting replies.
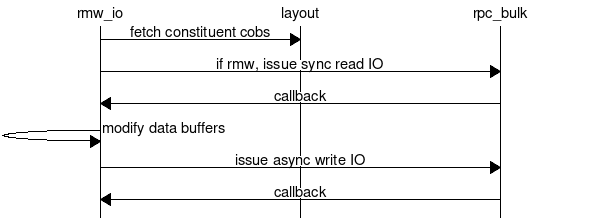
Subcomponent design
This DLD addresses only rmw_io component.
- The component will sit in IO path of Motr client code.
- It will detect if any incoming IO request spans a parity group only partially.
- In case of partial groups, it issues an inline read request to read the necessary blocks from parity group and get the data in memory.
- The thread blocks for completion of read IO.
- If incoming IO request was read IO, the thread will be returned along with the status and number of bytes read.
- If incoming IO request was write, the pages are modified in-place as per the user request.
- And then, write IO is issued for the whole parity group.
- Completion of write IO will send the status back to the calling thread.
Small IO requests
For small IO requests which do not span even a single parity group due to end-of-file occurring before parity group boundary,
- rest of the blocks are assumed to be zero and
- parity is calculated from valid data blocks only.
The file size will be updated in file inode and will keep a check on actual size.
For instance, with configuration like
- parity_group_width = 20K
- unit_size = 4K
- nr_data_units = 3
- nr_parity_units = 1
- nr_spare_units = 1
When a new file is written to with data worth 1K, there will be
- 1 partial data unit and
- 2 missing data units
in the parity group.
Here, parity is calculated with only one partial data unit (only valid block) and data from whole parity group will be written to the server.
While reading the same file back, IO request for only one block is made as mandated by file size.
The seemingly obvious wastage of storage space in such cases can be overcome by
- issuing IO requests only for units which have at least a single byte of valid file data and for parity units.
- For missing data units, there is no need to use zeroed out buffers since such buffers do not change parity.
- Ergo, parity will be calculated from valid data blocks only (falling within end-of-file)
Since sending network requests for IO is under control of client, these changes can be accommodated for irrespective of layout type. This way, the wastage of storage space in small IO can be restricted to block granularity.
Processing an IO request may be interrupted due to rconfc read lock revocation. At that point m0t1fs can't read configuration and all operations must be stopped. In that case all IO requests existing at the moment are marked as failed, and as the result client receives -ESTALE error code. The client can try IO operations later when a configuration can be read again.
- See also
- rmw-lspec-abort.
- Todo:
- In future, optimizations could be done in order to speed up small file IO with the help of client side cache.
- Note
- Present implementation of m0t1fs IO path uses get_user_pages() API to pin user-space pages in memory. This works just fine with page aligned IO requests. But read-modify-write IO will use APIs like copy_from_user() and copy_to_user() which can copy data to or from user-space for both aligned and non-aligned IO requests. Although for direct-IO and device IO requests, no copy will be done and it uses get_user_pages() API since direct-IO is always page aligned.
Subcomponent Data Structures
io_request - Represents an IO request call. It contains the IO extent, struct nw_xfer_request and the state of IO request. This structure is primarily used to track progress of an IO request. The state transitions of io_request structure are handled by m0_sm structure and its support for chained state transitions.
The m0_sm_group structure is kept as a member of in-memory superblock, struct m0t1fs_sb. All m0_sm structures are associated with this group.
- See also
- struct m0t1fs_sb.
io_req_state - Represents state of IO request call. m0_sm_state_descr structure will be defined for description of all states mentioned below.
io_req_type - Represents type of IO request.
- Todo:
- IO types like fault IO are not supported yet.
io_request_ops - Operation vector for struct io_request.
nw_xfer_request - Structure representing the network transfer part for an IO request. This structure keeps track of request IO fops as well as individual completion callbacks and status of whole request. Typically, all IO requests are broken down into multiple fixed-size requests.
nw_xfer_state - State of struct nw_xfer_request.
nw_xfer_ops - Operation vector for struct nw_xfer_request.
pargrp_iomap - Represents a map of io extents in given parity group. Struct io_request contains as many pargrp_iomap structures as the number of parity groups spanned by original index vector. Typically, the segments from pargrp_iomap::pi_ivec are round_{up/down} to nearest page boundary for segments from io_request::ir_ivec.
pargrp_iomap_rmwtype - Type of read approach used by pargrp_iomap in case of rmw IO.
pargrp_iomap_ops - Operation vector for struct pargrp_iomap.
data_buf - Represents a simple data buffer wrapper object. The embedded db_buf::b_addr points to a kernel page or a user-space buffer in case of direct IO.
target_ioreq - Collection of IO extents and buffers, directed toward particular component object in a parity group. These structures are created by struct io_request dividing the incoming struct iovec into members of parity group.
ast thread - A thread will be maintained per super block instance m0t1fs_sb to wake up on receiving ASTs and execute the bottom halves. This thread will run as long as m0t1fs is mounted. This thread will handle the pending IO requests gracefully when unmount is triggered.
The in-memory super block struct m0t1fs_sb will maintain
- a boolean indicating if super block is active (mounted). This flag will be reset by the unmount thread. In addition to this, every io request will check this flag while initializing. If this flag is reset, it will return immediately. This helps in blocking new io requests from coming in when unmount is triggered.
- atomic count of pending io requests. This will help while handling pending io requests when unmount is triggered.
- the "ast" thread to execute ASTs from io requests and to wake up the unmount thread after completion of pending io requests.
- a channel for unmount thread to wait on until all pending io requests complete.
The thread will run a loop like this...
So, while m0t1fs is mounted, the thread will keep running in loop waiting for ASTs.
When unmount is triggered, new io requests will be returned with an error code as m0t1fs_sb::csb_active flag is unset. For pending io requests, the ast thread will wait until callbacks from all outstanding io requests are acknowledged and executed.
Once all pending io requests are dealt with, the ast thread will exit waking up the unmount thread.
Abort is not supported at the moment in m0t1fs io code as it needs same functionality from layer beneath.
When bottom halves for m0_sm_ast structures are run, it updates target_ioreq::tir_rc and target_ioreq::tir_bytes with data from IO reply fop. Then the bottom half decrements nw_xfer_request::nxr_iofops_nr, number of IO fops. When this count reaches zero, io_request::ir_sm changes its state.
A callback function will be used to associate with m0_rpc_item::ri_ops:: rio_replied(). This callback will be invoked once rpc layer receives the reply rpc item. This callback will post the io_req_fop::irf_ast and will thus wake up the thread which executes the ASTs.
io_req_fop - Represents a wrapper over generic IO fop and its callback to keep track of such IO fops issued by same nw_xfer_request.
io_rpc_item_cb - Callback used to receive fop reply events.
io_bottom_half - Bottom-half function for IO request.
Magic value to verify sanity of struct io_request, struct nw_xfer_request, struct target_ioreq and struct io_req_fop. The magic values are used along with static m0_bob_type structures to assert run-time type identification.
Subcomponent Subroutines
In order to satisfy the requirement of an ioctl API for fully vectored scatter-gather IO (where multiple IO segments are directed at multiple file offsets), a new API will be introduced that will use a m0_indexvec structure to specify multiple file offsets.
In case of normal file->f_op->aio_{read/write} calls, the m0_indexvec will be created and populated by m0t1fs code, while in case of ioctl, it has to be provided by user-space.
io_request_invariant - Invariant for structure io_request.
nw_xfer_request_invariant - Invariant for structure nw_xfer_request.
data_buf_invariant_nr - A helper function to invoke invariant() for all data_buf structures in array pargrp_iomap::tir_databufs. It is on similar lines of m0_tl_forall() API.
target_ioreq_invariant - Invariant for structure target_ioreq.
pargrp_iomap_invariant - Invariant for structure pargrp_iomap.
pargrp_iomap_invariant_nr - A helper function to invoke pargrp_iomap_invariant() for all such structures in io_request::ir_iomaps.
data_buf_invariant - Invariant for structure data_buf.
io_req_fop_invariant - Invariant for structure io_req_fop.
io_request_init - Initializes a newly allocated io_request structure.
io_request_fini - Finalizes the io_request structure.
nw_xfer_req_prepare - Creates and populates target_ioreq structures for each member in the parity group. Each target_ioreq structure will allocate necessary pages to store file data and will create IO fops out of it.
nw_xfer_req_dispatch - Dispatches the network transfer request and does asynchronous wait for completion. Typically, IO fops from all target_ioreq::tir_iofops contained in nw_xfer_request::nxr_tioreqs list are dispatched at once. The network transfer request is considered as complete when callbacks for all IO fops from all target_ioreq structures are acknowledged and processed.
nw_xfer_req_complete - Does post processing for network request completion which is usually notifying struct io_request about completion.
State Specification
- Todo:
- A client cache is missing at the moment. With addition of cache, the states of an IO request might add up.
Threading and Concurrency Model
All IO fops resulting from IO request will be dispatched at once and the state machine (m0_sm) will wait for completion of read or write IO. Incoming callbacks will be registered with the m0_sm state machine where the bottom half functions will be executed on the "ast" thread. The ast thread and the system call thread coordinate by using m0_sm_group::s_lock mutex.
- See also
- State machine. Concurrency section of State machine.
- Todo:
- In future, with introduction of Resource Manager, distributed extent locks have to be acquired or released as needed.
NUMA optimizations
None.
IO request aborting
When m0t1fs rconfc lost read lock it can't read configuration and all existing IO requests must be stopped at the current point of progress. Once rconfc loses read lock, m0_rconfc::rc_expired_cb is triggered. It sets m0t1fs_sb::csb_rlock_revoked to true and cancel sessions to IO services. ioreq_iosm_handle checks the flag after its subroutines and interrupt handling, if the read lock is revoked.
rmw-degraded-readIO
This section describes the provision for read IO while SNS repair is going on. Motr uses data redundancy patterns like pdclustered RAID to recover in case of a failed device or node. Parity is calculated across a parity group and stored on persistent media so as to recover in case disaster strikes. Since file data is distributed across multiple target objects (cobs in this case), failure of a read IO request for any cobs could result into triggering of degraded mode read IO.
rmw-dgreadIO-req
- R.dg.mode.readIO.efficient The implementation shall provide an efficient way of handling degraded mode read IO requests keeping the performance hit to a minimum.
- R.dg.mode.readIO.clientOnly The implementation shall stick to retrieving the lost data unit by reading rest of the data units and/or parity unit from given parity group. There is no interaction with server sns repair process.
rmw-dgreadIO-highlights
A new state will be introduced to represent degraded mode read IO. The degraded mode state will find out the affected parity groups from the failed IO fop and will start read for missing data units and/or parity units. Amount of data to be read depends on type of read approach undertaken by the pargrp group (struct pargrp_iomap), namely
- read_old Read rest of the data units as well as parity units.
- read_rest Read parity units only since all other data units are already present.
rmw-dgreadIO-lspec
A new state DEGRADED_READING will be introduced to handle degraded read IO. The error in IO path will be introduced by a fault injection point which will trigger degraded mode and IO state machine will transition into degraded mode state.
Both simple read IO and read-modify-write IO will be supported in the process. The state transition of IO state machine in both these case will be as given below...
- simple readIO
READING –> DEGRADED_READING
DEGRADED_READING –> READ_COMPLETE
READ_COMPLETE –> REQ_COMPLETE. - read-modify-write IO
READING –> DEGRADED_READING
DEGRADED_READING –> READ_COMPLETE
READ_COMPLETE –> WRITING
WRITING –> WRITE_COMPLETE
WRITE_COMPLETE –> REQ_COMPLETE.
Caller does not get any intimation of degraded mode read IO. It can only be realised by a little lower throughput numbers since degraded mode readIO state has to do more IO.
A modified state transition diagram can be seen at State specification.
- See also
- rmw-lspec-state.
The existing rmw data structures will be modified to accommodate degraded mode read IO as mentioned below...
- struct io_request
- It is the top-level data structure which represents an IO request and state machine will be changed by addition of degraded read IO state.
- Routine iosm_handle() will be modified to handle degraded mode state and transition into normal read or write states once degraded mode read IO is complete.
- New routines will be added to handle retrieval of lost data unit/s from rest of data units and parity units.
- struct pargrp_iomap
- a state enumeration will be added indicating the state of parity group is either HEALTHY or DEGRADED.
- Pages from the data units and/or parity units that need to be read in order to retrieve lost data unit will be marked with a special page flag to distinguish between normal IO and degraded mode IO.
- Since every parity group follows either read-old or read-rest approach while doing read-modify-write, special routines catering to degraded mode handling of these approaches will be developed.
- read_old Since all data units may not be available in this approach, all remaining data units are read. Parity units are read already.
- read_rest All data units are available but parity units are not. Hence, parity units are read in order to retrieve lost data.
- simple_read A routine will be written in order to do read for rest of data units and/or parity units for a simple read IO request.
- struct dgmode_readvec
- a new data structure to hold m0_indexvec and m0_bufvec for pages that needed to be read from server.
- struct nw_xfer_request
- nw_xfer_io_prepare() operation will be modified to distribute pages amongst target objects for degraded mode read IO.
- struct target_ioreq
- a new data structure (struct dgmode_readvec) will be introduced to hold pages from degraded mode read IO. This serves 2 purposes.
- Segregate degraded mode read IO from normal IO and
- Normal IO requests will not be affected by degraded mode read IO code.
- a new data structure (struct dgmode_readvec) will be introduced to hold pages from degraded mode read IO. This serves 2 purposes.
- target_ioreq_iofops_prepare()
- This routine will be changed to handle IO for both healthy mode as well as degraded mode IO.
- enum page_attr
- a new flag (PA_DGMODE_READ) will be added to identify pages issued for degraded mode read IO.
io_bottom_half
- This routine will be modified to host a fault injection point which will simulate the behavior of system in case of read IO failure.
Along with all these changes, almost all invariants will be changed as necessary.
rmw-dgreadIO-limitations
- Since present implementation of read-modify-write IO supports only XOR due to lack of differential calculation of parity for Reed-Solomon algorithm only single failures will be supported as XOR supports single failures only.
- Since there is no provision in current bulk transfer/rpc bulk API to pin-point failed segment/s in given IO vector during bulk transfer, all parity groups referred to by segments in failed read fop will be tried for regeneration of lost data.
rmw-dgreadIO-conformance
I.dg.mode.readIO.efficient The implementation will use async way of sending fops and waiting for them. All pages are aggregated so all pending IO is dispatched at once. Besides, new IO vectors will be used in target_ioreq structures so as to segregate them from normal IO vector.
I.dg.mode.readIO.clientOnly The implementation will use parity regeneration APIs from parity math library so that there is no need to communicate with server.
rmw-dgreadIO-ut
The existing rmw UT will be modified to accommodate unit tests made to stress the degraded mode read IO code.
- Test:
- Prepare a simple read IO request and enable the fault injection point in order to simulate behavior in case of degraded mode read IO. Keep a known pattern of data in data units so as to verify the contents of lost data unit after degraded mode read IO completes.
- Test:
- Prepare a read-modify-write IO request with one parity group and enable fault injection point in io_bottom_half. Keep only one valid data unit in parity group so as to ensure read_old approach is used. Trigger the fault injection point to simulate degraded mode read IO and verify the contents of read buffers after degraded mode read IO completes. The contents of read buffers should match the expected data pattern.
- Test:
- Preapre a read-modify-write IO request with one parity group and enable the fault injection point in io_bottom_half. Keep all but one valid data units in parity group so as to ensure read-rest approach is used. Trigger the fault injection point to simulate degraded mode read IO and verify contents of read buffers after degraded mode read IO completes. The contents of read buffers should match the expected data pattern.
rmw-degraded-writeIO
This section describes the internals of degraded mode write IO, an update operation, going concurrently with SNS repair process. Since SNS repair and write IO can operate on same file at a file, a distributed lock is used to synchronize access to files. This distributed lock will be used by Motr client IO code as well as the SNS repair process. Once lock is acquired on the given file, write IO request will send IO fops to respective healthy devices and will return the number of bytes written to the end user.
rmw-dgwriteIO-req
R.dg.mode.writeIO.consistency The implementation shall keep the state of file system to be consistent after degraded mode write IO requests. Ergo, any further read IO requests on same extents should fetch the expected data.
R.dg.mode.writeIO.efficient The implementation shall provide an efficient way of provisioning degraded write IO support, keeping the performance hits to a minimum.
R.dg.mode.writeIO.dist_locks The implementation shall use cluster wide distributed locks in order to synchronize access between client IO path and SNS repair process. Although due to unavailability of distributed locks, the implementation shall stick to a working business logic which can be demonstrated through appropriate test cases. Distributed locks shall be introduced as and when they are available.
rmw-dgwriteIO-highlights
A new state will be introduced in IO request state machine to handle all details of degraded mode write IO. The IO request shall try to acquire a distributed lock on the given file and will block until lock is granted. All compute operations like processing parity groups involved and distributing file data amongst different target objects shall be done. Issuing of actual IO fops is not done until distributed lock is not granted. The degraded mode write IO request will find out the current window of SNS repair process in order to find out whether repair process has repaired given file or not. Accordingly write IO fops will be sent to devices (cobs) and total number of bytes written will be returned to end user.
rmw-dgwriteIO-depends
- Distributed lock API is expected from resource management subsystem which will take care of synchronizing access to files. The Motr client IO path will request a distributed lock for given file and will block until lock is not granted. Similarly, SNS repair should acquire locks on global files which are part of current sliding window while repairing.
- An API is expected from SNS subsystem which will find out if repair has completed for input global file fid or not. Since the SNS repair sliding window consists of a set of global fids which are currently under repair, assuming the lexicographical order of repair, the API should return whether input global fid has been repaired or not.
- When number of spare units in a storage pool is greater than one, algorithm like Reed & Solomon is used to generate parity. During repair, the SNS repair process recovers the lost data using parity recovery algorithms. If number of parity units is greater than one, the order in which lost units are stored on spare units (which recovered data unit will be stored on which spare unit) should be well known. It should be similar to degraded mode write IO use-case where data for lost devices needs to be redirected to spare units.
An example can illustrate this properly -- Consider a storage pool with parameters N = 8, K = 2, P = 12
- Assuming device# 2 and #3 failed and SNS repair is triggered.
- When SNS repair recovers lost data for 2 lost devices, it needs to be stored on the 2 spare units in all parity groups.
- Now the order in which this data is stored on spare units matters and should be same with the order used by Motr client IO code in cases where data for lost devices need to be redirected towards corresponding spare units in same parity group. For instance,
- Recovered unit# 2 stored on Spare unit# 0 AND
- Recovered unit# 3 stored on Spare unit# 1. OR
- Recovered unit# 2 stored on Spare unit# 1 AND
- Recovered unit# 3 stored on Spare unit# 0.
- Same routine will be used by Motr degraded write IO code path as well as SNS repair code to decide this order.
rmw-dgwriteIO-lspec
A new state DEGRADED_WRITING will be introduced which will take care of handling degraded write IO details.
- As the first step, IO path will try to acquire distributed lock on the given file. This code will be a stub in this case, since distributed locks are not available yet. IO path will block until the distributed lock is not granted.
- When SNS repair starts, the normal write IO will fail with an error.
- The IO reply fop will be incorporated with a U64 field which will indicate whether SNS repair has finished or is yet to start on given file fid. Alongside, the IO request fop will be incorporated with global fid since since it is not present in current IO request fop and it is needed to find out whether SNS repair has completed for this global fid or not. The SNS repair subsystem will invoke an API
- See also
- rmw-dgwriteIO-depends which will return either a boolean value indicating whether repair has completed for given file or not. Structure io_req_fop will be incorporated with a boolean field to indicate whether SNS repair has completed for given global fid or not.
- Use-case 1: If SNS repair is yet to start on given file, the write IO fops for the failed device can be completely ommitted since there is enough information in parity group which can be used by SNS repair to re-generate lost data.
- If the lost unit is file data, it can be re-generated using parity recover algorithms since parity is updated in this case.
- If lost unit is parity, it can be re-calculated using parity generation algorithm.
- Use-case 2: If SNS repair has completed for given file, the write IO fops for the failed device can be redirected to spare units since by that time, SNS repair has re-generated data and has dumped it on spare units.
- A mechanism is needed from SNS repair subsystem to find out which unit from parity group maps to which spare unit.
- See also
- rmw-dgwriteIO-depends
- A mechanism is needed from SNS repair subsystem to find out which unit from parity group maps to which spare unit.
- The state machine will transition as follows.
WRITING –> WRITE_COMPLETE
WRITE_COMPLETE –> DEGRADED_WRITING
DEGRADED_WRITING –> WRITE_COMPLETE- See also
- State Specification
- Existing rmw IO structures will be modified as mentioned below.
- struct io_request
- State machine will be changed by addition of a new state which will handle degraded mode write IO.
- ioreq_iosm_handle() will be modified to handle new state whenever write IO fails with a particular error code.
- struct nw_xfer_request
- Needs change in nw_xfer_tioreq_map() to factor out common code which will be shared with the use-case where repair has completed for given file and lost data is re-generated on spare units. In this case, write IO fops on failed device need to be redirected to spare units.
- struct target_ioreq
- Struct dgmode_readvec will be reused to work for degraded mode write IO.
- The routine target_ioreq_seg_add() will be modified to accommodate pages belonging to use-case where repair has completed for given file and the pages belonging to failed device need to be diverted to appropriate spare unit in same parity group.
- struct io_request
- IO reply on-wire fop will be enhanced with a U64 field which will imply if SNS repair has completed for global fid in IO request fop or not. This field is only used in case of ongoing SNS repair. It is not used during healthy pool state.
- End user is unaware of degraded mode write IO. It can be characterised by low IO throughput.
rmw-dgwriteIO-limitations
- Since degraded mode write IO requires distributed locks and distributed locks are not available yet, the implementation tries to stick to implement the business logic of degraded mode write IO. Since by using file granularity distributed locks, either SNS repair or write IO request will have exclusive access to given file at a time and hence this task tries to implement the business logic of degraded mode write IO assuming the distributed lock has been acquired on given file. Later when distributed locks are available in Motr, they will be incorporated in Motr client IO path and SNS repair code.
- As is the case with every other subcomponent of m0t1fs, only XOR is supported at the moment. And it can recover only one failure in a storage pool at a time.
rmw-dgwriteIO-conformance
I.dg.mode.writeIO.consistency In either of possible use-cases, write IO request will write enough data in parity group so that the data for lost device is either
- re-generated by SNS repair process (repair yet to happen on given file) OR
- is available on spare units (repair completed for given file) This can be illustrated by having a subsequent read IO on same file extent which can confirm file contents are sane.
I.dg.mode.writeIO.efficient The implementation shall provide an async way of sending fops. All pages are aggregated and sent as one/more IO fops. Code is written in such a manner that normal IO requests are not affected by degraded mode functionality.
I.dg.mode.writeIO.dist_locks The implementation shall use dummy calls for acquiring distributed locks since distributed locks are not yet available in Motr. Later when distributed locks are available in Motr, they will be incorporated in client IO code.
rmw-dgwriteIO-ut
The existing UT will be modified in order to accommodate tests for degraded mode write IO. The unit tests will focus on checking function level correctness, while ST will use different combinations of file sizes to be repaired in order to exercise degraded mode write IO code.
The ST especially can exercise the 2 use-cases mentioned in logical spec,
- See also
- rmw-dgwriteIO-lspec.
- Test:
- In order to exercise the use-case where SNS repair is yet to start on the file,
- Write 2 files, one which is sufficiently big in size (for instance, worth thousands of parity groups in size) and another which is smaller (worth one/two parity groups in size).
- Keep a known data pattern in the smaller file which can be validated for correctness.
- Write the big file first to m0t1fs and then the smaller one.
- Start SNS repair manually by specifying failed device.
- Repair will start in lexicographical order and will engage the bigger file first.
- Issue a write IO request immediately (while repair is going on) on smaller file which will exercise the use-case of given file still to be repaired by SNS repair process.
- Test:
- In order to exercise the use-case where SNS repair has completed for given file,
- Write 2 files, one which is sufficiently big in size (worth thousands of parity groups in size) and another which is smaller (worth one/two parity groups in size).
- Keep a known data pattern in smaller file in order to verify the write IO later.
- Write the smaller file first to m0t1fs and then the bigger one.
- Start SNS repair manually by specifying failed device.
- Repair will start in lexicographical order and will engage the smaller file first.
- Issue a write IO request immediately (while repair is going on) on the smaller file which will exercise the use-case of given file being repaired by SNS repair.
Conformance
- I.m0t1fs.rmw_io.rmw The implementation maintains an io map per parity group in a data structure pargrp_iomap. The io map rounds up/down the incoming io segments to nearest page boundaries. The missing data will be read first from data server (later from client cache which is missing at the moment and then from data server). Data is copied from user-space at desired file offsets and then it will be sent to server as a write IO request.
- I.m0t1fs.rmw_io.efficient The implementation uses an asynchronous way of waiting for IO requests and does not send the requests one after another as is done with current implementation. This leads in only one conditional wait instead of waits proportional to number of IO requests as is done with current implementation.
Unit Tests
The UT will exercise following unit test scenarios.
- Todo:
- However, with all code in kernel and no present UT code for m0t1fs, it is still to be decided how to write UTs for this component.
- Test:
- Issue a full parity group size IO and check if it is successful. This test case should assert that full parity group IO is intact with new changes.
- Test:
- Issue a partial parity group read IO and check if it successful. This test case should assert the fact that partial parity group read IO is working properly.
- Test:
- Issue a partial parity group write IO and check if it is successful. This should confirm the fact that partial parity group write IO is working properly.
- Test:
- Write very small amount of data (10 - 20 bytes) to a newly created file and check if it is successful. This should stress 2 boundary conditions
- a partial parity group write IO request and
- unavailability of all data units in a parity group. In this case, the non-existing data units will be assumed as zero filled buffers and the parity will be calculated accordingly.
- Test:
- Kernel mode fault injection can be used to inject failure codes into IO path and check for results.
- Test:
- Test read-rest test case. If io request spans a parity group partially, and reading the rest of parity group units is more economical (in terms of io requests) than reading the spanned extent, the feature will read rest of parity group and calculate new parity. For instance, in an 8+1+1 layout, first 5 units are overwritten. In this case, the code should read rest of the 3 units and calculate new parity and write 9 pages in total.
- Test:
- Test read-old test case. If io request spans a parity group partially and reading old units and calculating parity iteratively is more economical than reading whole parity group, the feature will read old extent and calculate parity iteratively. For instance, in an 8+1+1 layout, first 2 units are overwritten. In this case, the code should read old data from these 2 units and old parity. Then parity is calculated iteratively and 3 units (2 data + 1 parity) are written.
System Tests
A bash script will be written to send partial parity group IO requests in loop and check the results. This should do some sort of stress testing for the code.
Analysis
Only one io_request structure is created for every system call. Each IO request creates sub requests proportional to number of blocks addressed by io vector. Number of IO fops created is also directly proportional to the number of data buffers.
References
- Detailed level design HOWTO (an older document on which this style guide is partially based) : For documentation links, please refer to this file : doc/motr-design-doc-list.rst
