- Overview
- Definitions
- Requirements
- Dependencies
- Design Highlights
- Functional Specification
- LNet Transport
- XO Interface
- Logical Specification - Component Overview
- End Point Support
- Transfer Machine Start
- Transfer Machine Termination
- Synchronous Network Buffer Event Delivery
- Transfer Machine Event Processing Thread
- Network Buffer Descriptor
- Buffer operations
- State Specification
- Threading and Concurrency Model
- NUMA optimizations
- LNet Transport
- Conformance
- Unit Tests
- System Tests
- Analysis
- References
Overview
This document describes the Motr network transport for LNet. The transport is composed of multiple layers. The document describes the layering and then focuses mainly on the transport operations layer.
The design of the other layers can be found here:
- LNet Buffer Event Circular Queue DLD
- LNet Transport Kernel Core DLD
- LNet Transport User Space Core DLD
Definitions
- HLD of Motr LNet Transport : For documentation links, please refer to this file : doc/motr-design-doc-list.rst
Requirements
- r.m0.net.xprt.lnet.transport-variable The implementation shall name the transport variable as specified in the HLD.
- r.m0.net.lnet.buffer-registration Provide support for hardware optimization through buffer pre-registration.
- r.m0.net.xprt.lnet.end-point-address The implementation should support the mapping of end point address to LNet address as described in the Refinement section of the HLD.
- r.m0.net.xprt.lnet.multiple-messages-in-buffer Provide support for this feature as described in the HLD.
- r.m0.net.xprt.lnet.dynamic-address-assignment Provide support for dynamic address assignment as described in the HLD.
- r.m0.net.xprt.lnet.processor-affinity The implementation must support processor affinity as described in the HLD.
- r.m0.net.xprt.lnet.user-space The implementation must accommodate the needs of the user space LNet transport.
- r.m0.net.synchronous-buffer-event-delivery The implementation must provide support for this feature as described in the HLD.
Dependencies
-
The Networking Module. Some modifications are required:
The design adds two additional fields to the m0_net_buffer structure:
These fields are required to be set to non-zero values in receive buffers, and control the reception of multiple messages into a single receive buffer.
Additionally, the semantics of the
nb_epfield is modified to not require the end point of the active transfer machine when enqueuing a passive buffer. This effectively says that there will be no constraint on which transfer machine performs the active operation, and the application with the passive buffer is not required to know the address of this active transfer machine in advance. This enables the conveyance of the network buffer descriptor to the active transfer machine through intermediate proxies, and the use of load balancing algorithms to spread the I/O traffic across multiple servers.The m0_net_tm_confine() subroutine is added to set the processor affinity for transfer machine thread if desired. This results in an additional operation being added to the m0_net_xprt_ops structure:
The behavior of the m0_net_buffer_event_post() subroutine is modified slightly to allow for multiple buffer events to be delivered for a single receive buffer, without removing it from a transfer machine queue. This is indicated by the M0_NET_BUF_RETAIN flag.
The design adds the following fields to the m0_net_transfer_mc structure to support the synchronous delivery of network buffer events:
By default,
ntm_bev_auto_deliveris set totrue. In addition the following subroutines are defined:- m0_net_buffer_event_deliver_all()
- m0_net_buffer_event_deliver_synchronously()
- m0_net_buffer_event_pending()
- m0_net_buffer_event_notify()
This results in corresponding operations being added to the m0_net_xprt_ops structure:
-
The Bitmap Module. New subroutines to copy a bitmap and to compare bitmaps are required. The copy subroutine should be refactored out of the processors_copy_m0bitmap() subroutine.
-
The Processor API for the application to determine processor bitmaps with which to specify thread affinity.
-
The Thread Module. Modifications are required in m0_thread_init() subroutine or a variant should be provided to support thread creation with processor affinity set. This is essential for the kernel implementation where processor affinity can only be set during thread creation.
Design Highlights
- Common user and kernel space implementation over an underlying "Core" I/O layer that communicates with the kernel LNet module.
- Supports the reception of multiple messages in a single receive buffer.
- Provides processor affinity.
- Support for hardware optimizations in buffer access.
- Support for dynamic transfer machine identifier assignment.
- Efficient communication between user and kernel address spaces in the user space transport through the use of shared memory. This includes the efficient conveyance of buffer operation completion event data through the use of a circular queue in shared memory, and the minimal use of system calls to block for events.
Logical Specification
- Component Overview
- End Point Support
- Transfer Machine Start
- Transfer Machine Termination
- Synchronous Network Buffer Event Delivery
- Transfer Machine Event Processing Thread
- Network Buffer Descriptor
- Buffer operations
- State Specification
- Threading and Concurrency Model
- NUMA optimizations
Component Overview
The focus of the LNet transport is the implementation of the asynchronous semantics required by the Motr Networking layer. I/O is performed by an underlying "core" layer, which does the actual interaction with the Lustre LNet kernel module. The core layer permits the LNet transport code to be written in an address space agnostic fashion, as it offers the same interface in both user and kernel space.
The relationship between the various components of the LNet transport and the networking layer is illustrated in the following UML diagram.

End Point Support
The transport defines the following structure for the internal representation of a struct m0_net_end_point.
The length of the structure depends on the length of the string representation of the address, which must be saved in the xe_addr array. The address of the xe_ep field is returned as the external representation.
The end point data structure is not associated internally with any LNet kernel resources.
The transport does not support dynamic addressing: i.e. the addr parameter can never be NULL in the m0_net_end_point_create() subroutine. However, it supports the dynamic assignment of transfer machine identifiers as described in the HLD, but only for the addr parameter of the m0_net_tm_start() subroutine.
A linked list of all end point objects created for a transfer machine is maintained in the m0_net_transfer_mc::ntm_end_points list. Objects are added to this list as a result of the application invoking the m0_net_end_point_create() subroutine, or as a side effect of receiving a message. Access to this list is protected by the transfer machine mutex.
Transfer Machine Start
The m0_net_tm_start() subroutine is used to start a transfer machine, which results in a call to nlx_xo_tm_start(). The subroutine decodes the end point address using the nlx_core_ep_addr_decode() subroutine. It then starts the background event processing thread with the desired processor affinity. The thread will complete the transfer machine start up and deliver its state change event.
The event processing thread will call the nlx_core_tm_start() subroutine to create the internal LNet EQ associated with the transfer machine. This call also validates the transfer machine's address, and assigns a dynamic transfer machine identifier if needed. It will then post a state change callback to transition the transfer machine to its normal operational state, or fail it if any error is encountered.
Transfer Machine Termination
Termination of a transfer machine is requested through the m0_net_tm_stop() subroutine, which results in a call to nlx_xo_tm_stop(). The latter ensures that the transfer machine's thread wakes up by signaling on the nlx_xo_transfer_mc::xtm_ev_cond condition variable.
When terminating a transfer machine the application has a choice of draining current operations or aborting such activity. If the latter choice is made, then the transport must first cancel all operations.
Regardless, the transfer machine's event processing thread completes the termination process. It waits until all buffer queues are empty and any ongoing synchronous network buffer delivery has completed, then invokes the nlx_core_tm_stop() subroutine to free the LNet EQ and other resources associated with the transfer machine. It then posts the transfer machine state change event and terminates itself. See Transfer Machine Event Processing Thread for further detail.
Synchronous Network Buffer Event Delivery
The transport supports the optional synchronous network buffer event delivery as required by the HLD. The default asynchronous delivery of buffer events is done by the Transfer Machine Event Processing Thread. Synchronous delivery must be enabled before the transfer machine is started, and is indicated by the value of the m0_net_transfer_mc::ntm_bev_auto_deliver value being false.
The nlx_xo_bev_deliver_sync() transport operation is invoked to disable the automatic delivery of buffer events. The subroutine simply returns without error, and the invoking m0_net_buffer_event_deliver_synchronously() subroutine will then set the value of m0_net_transfer_mc::ntm_bev_auto_deliver value to false.
The nlx_xo_bev_pending() transport operation is invoked from the m0_net_buffer_event_pending() subroutine to determine if there are pending network buffer events. It invokes the nlx_core_buf_event_wait() subroutine with a timeout of 0 and uses the returned status value to determine if events are present or not.
The nlx_xo_bev_notify() transport operation is invoked from the m0_net_buffer_event_notify() subroutine. It sets the nlx_xo_transfer_mc::xtm_ev_chan value to the specified wait channel, and signals on the nlx_xo_transfer_mc::xtm_ev_cond condition variable to wake up the event processing thread.
The nlx_xo_bev_deliver_all() transport operation is invoked from the m0_net_buffer_event_deliver_all() subroutine. It attempts to deliver all pending events. The transfer machine lock is held across the call to the nlx_core_buf_event_get() subroutine to serialize "consumers" of the circular buffer event queue, but is released during event delivery. The m0_net_transfer_mc::ntm_callback_counter field is incremented across the call to prevent premature termination when operating outside of the protection of the transfer machine mutex. This is illustrated in the following pseudo-code for nlx_xo_bev_deliver_all():
Transfer Machine Event Processing Thread
The default behavior of a transfer machine is to automatically deliver buffer events from the Core API's event queue to the application. The Core API guarantees that LNet operation completion events will result in buffer events being enqueued in the order the API receives them, and, in particular, that multiple buffer events for any given receive buffer will be ordered. This is very important for the transport, because it has to ensure that a receive buffer operation is not prematurely flagged as dequeued.
The transport uses exactly one event processing thread to process buffer events from the Core API. This has the following advantages:
- The implementation is simple.
- It implicitly race-free with respect to receive buffer events.
Applications are not expected to spend much time in the event callback, so this simple approach is acceptable.
The application can establish specific processor affiliation for the event processing thread with the m0_net_tm_confine() subroutine prior to starting the transfer machine. This results in a call to the nlx_xo_tm_confine() subroutine, which makes a copy of the desired processor affinity bitmask in nlx_xo_transfer_mc::xtm_processors.
In addition to automatic buffer event delivery, the event processing thread performs the following functions:
- Notify the presence of buffer events when synchronous buffer event delivery is enabled
- Transfer machine state change event posting
- Buffer operation timeout processing
- Logging of statistical data
The functionality of the event processing thread is best illustrated by the following pseudo-code:
(The C++ style comments above are used only because the example is embedded in a Doxygen C comment. C++ comments are not permitted by the Motr coding style.)
A few points to note on the above pseudo-code:
- The thread blocks in the nlx_core_buf_event_wait() if the default automatic buffer event delivery mode is set, or on the nlx_xo_transfer_mc::xtm_ev_cond condition variable otherwise. In the latter case, it may also block in the nlx_core_buf_event_wait() subroutine if the condition variable is signaled by the nlx_xo_bev_notify() subroutine.
- The transfer machine mutex is obtained across the call to dequeue buffer events to serialize with the "other" consumer of the buffer event queue, the nlx_xo_buf_add() subroutine that invokes the Core API buffer operation initiation subroutines. This is because these subroutines may allocate additional buffer event structures to the queue.
- The nlx_xo_bev_deliver_all() subroutine processes as many events as it can each time around the loop. The call to the nlx_core_buf_event_wait() subroutine in the user space transport is expensive as it makes a device driver
ioctlcall internally. - The thread is responsible for terminating the transfer machine and delivering its termination event. Termination serializes with concurrent invocation of the nlx_xo_bev_deliver_all() subroutine in the case of synchronous buffer event delivery.
- The timeout value can vary depending on the mode of operation. Synchronous network delivery is best served by a long timeout value (in the order of a minute), at least up to the time that the transfer machine is stopping. Automatic buffer event delivery is better served by a short timeout value (in the order of a second). This is because in the user space transport the thread would be blocked in an ioctl call in the kernel, and would not respond in a lively manner to a shutdown request. The timeout value is also dependent on whether the transfer machine is stopping, the buffer operation timeout check period and the statistical recording period.
Network Buffer Descriptor
The transport has to define the format of the opaque network buffer descriptor returned to the application, to encode the identity of the passive buffers.
The data structure will be defined by the Core API along the following lines:
The nlx_core_buf_desc_encode() and nlx_core_buf_desc_decode() subroutines are provided by the Core API to generate and process the descriptor. All the descriptor fields are integers, the structure is of fixed length and all values are in little-endian format. No use is made of either the standard XDR or the Motr Xcode modules.
The transport will handle the conversion of the descriptor into its opaque over the wire format by simply copying the memory area, as the descriptor is inherently portable.
Buffer operations
Buffer operations are initiated through the m0_net_xprt_ops::xo_buf_add() operation which points to the nlx_xo_buf_add() subroutine. The subroutine will invoke the appropriate Core API buffer initiation operations.
In passive bulk buffer operations, the transport must first obtain suitable match bits for the buffer using the nlx_core_buf_desc_encode() subroutine. The transport is responsible for ensuring that the assigned match bits are not in use currently; however this step can be ignored with relative safety as the match bit space is very large and the match bit counter will only wrap around after a very long while. These match bits should also be encoded in the network buffer descriptor that the transport must return.
In active bulk buffer operations, the size of the active buffer should be validated against the size of the passive buffer as given in its network buffer descriptor. The nlx_core_buf_desc_decode() subroutine should be used to decode the descriptor.
State Specification
The transport does not introduce its own state model but operates within the framework defined by the Motr Networking Module. In general, resources are allocated to objects of this module by the underlying Core API, and they have to be recovered upon object finalization, and in the particular case of the user space transport, upon process termination if the termination was not orderly.
The resources allocated to the following objects are particularly called out:
Network buffers enqueued with a transfer machine represent operations in progress. Until they get dequeued, the buffers are associated internally with LNet kernel module resources (MDs and MEs) allocated on their behalf by the Core API.
The transfer machine is associated with an LNet event queue (EQ). The EQ must be created when the transfer machine is started, and destroyed when the transfer machine stops. The transfer machine operates by default in an asynchronous network buffer delivery mode, but can also provide synchronous network buffer delivery for locality sensitive applications like the Motr request handler.
Buffers registered with a domain object are potentially associated with LNet kernel module resources and, if the transport is in user space, additional kernel memory resources as the buffer vector is pinned in memory. De-registration of the buffers releases these resources. The domain object of a user space transport is also associated with an open file descriptor to the device driver used to communicate with the kernel Core API.
End point structures are exposed externally as struct m0_net_end_point, but are allocated and managed internally by the transport with struct nlx_xo_ep. They do not use LNet resources, but just transport address space memory. Their creation and finalization is protected by the transfer machine mutex. They are reference counted, and the application must release all references before attempting to finalize a transfer machine.
Threading and Concurrency Model
The transport inherits the concurrency model of the Motr Networking Module. All transport operations are protected by some lock or object state, as described in the document RPC Bulk Transfer Task Plan. For documentation links, please refer to this file : doc/motr-design-doc-list.rst . The Core API is designed to work with this same locking model. The locking order figure is repeated here for convenience:
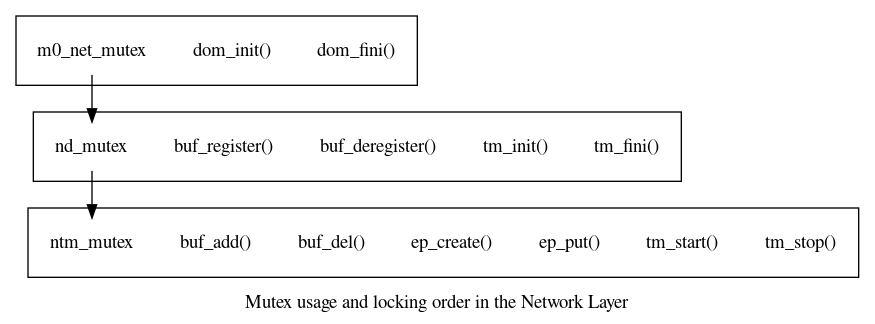
The transport only has one thread, its event processing thread. This thread uses the transfer machine lock when serialization is required by the Core API, and also when creating or looking up end point objects when processing receive buffer events. Termination of the transfer machine is serialized with concurrent invocation of the nlx_xo_bev_deliver_all() subroutine in the case of synchronous buffer event delivery by means of the m0_net_transfer_mc::ntm_callback_counter field. See Synchronous Network Buffer Event Delivery and Transfer Machine Event Processing Thread for details.
NUMA optimizations
The application can establish specific processor affiliation for the event processing thread with the m0_net_tm_confine() subroutine prior to starting the transfer machine. Buffer completion events and transfer machine state change events will be delivered through callbacks made from this thread.
Even greater locality of reference is obtained with synchronous network buffer event delivery. The application is able to co-ordinate references to network objects and other objects beyond the scope of the network module.
Conformance
- i.m0.net.xprt.lnet.transport-variable The transport variable
m0_net_lnet_xprtis provided. - i.m0.net.lnet.buffer-registration Buffer registration is required in the network API and results in the corresponding nlx_xo_buf_register() subroutine call at the LNet transport layer. This is where hardware optimization can be performed, once LNet provides such APIs.
- i.m0.net.xprt.lnet.end-point-address Mapping of LNet end point address is handled in the Core API as described in the LNet Transport Core API.
- i.m0.net.xprt.lnet.multiple-messages-in-buffer Fields are provided in the m0_net_buffer to support multiple message delivery, and the event delivery model includes the delivery of buffer events for receive buffers that do not always dequeue the buffer.
- i.m0.net.xprt.lnet.dynamic-address-assignment Dynamic transfer machine identifier assignment is provided by nlx_core_tm_start().
- i.m0.net.xprt.lnet.processor-affinity The m0_net_tm_confine() API is provided and the LNet transport provides the corresponding nlx_xo_tm_confine() function.
- i.m0.net.xprt.lnet.user-space The user space implementation of the Core API utilizes shared memory and reduces context switches required for user-space event processing through the use of a circular queue maintained in shared memory and operated upon with atomic operations.
- i.m0.net.synchronous-buffer-event-delivery See Synchronous Network Buffer Event Delivery and Transfer Machine Event Processing Thread for details.
Unit Tests
To control symbol exposure, the transport code is compiled using a single C file that includes other C files with static symbols. Unit testing will take advantage of this setup and use conditional renaming of symbols to intercept specific internal interfaces.
The following tests will be performed for the transport operation (xo) layer with a fake Core API. Tests involving the fake Core API ensure that the transport operation layer makes the correct calls to the Core API.
- Test:
- Multiple domain creation will be tested.
- Test:
- Buffer registration and deregistration will be tested.
- Test:
- Multiple transfer machine creation will be tested.
- Test:
- Test that the processor affinity bitmask is set in the TM.
- Test:
- The transfer machine state change functionality.
- Test:
- Initiation of buffer operations will be tested.
- Test:
- Delivery of synthetic buffer events will be tested, including multiple receive buffer events for a single receive buffer. Both asynchronous and synchronous styles of buffer delivery will be tested.
- Test:
- Management of the reference counted end point objects; the addresses themselves don't have to valid for these tests.
- Test:
- Encoding and Decoding of the network buffer descriptor will be tested.
- Test:
- Orderly finalization will be tested.
System Tests
- Test:
- The
bulkpingsystem test program will be updated to include support for the LNet transport. This program will be used to test communication between end points on the same system and between remote systems. The program will offer the ability to dynamically allocate a transfer machine identifier when operating in client mode.
Analysis
In general, the transport operational layer simply routes data too and from the Core API; this behavior is analyzed in LNet Transport Kernel Core DLD.
An area of concern specific to the transport operations layer is the management of end point objects. In particular, the time taken to search the list of end point objects is of O(N) - i.e. a linear search through the list, which is proportional to the number of list items. This search may become expensive if the list grows large - items on the list are reference counted and it is up to the application to release them, not the transport.
The internal end point address fields are all numeric and easily lend themselves to a hash based strategy (the NID value is the best candidate key). The tricky part of any hashing scheme would be to determine what hash function would result in a reasonably even distribution over a set of hash buckets; this is not as bad as it sounds, because even in the worst case, it would degenerate to the linear search we have at present.
Ultimately, the choice of whether to use hashing or not depends on what the behavior of a Motr server will be like in steady state: if end points are released fairly rapidly, the linked list implementation will suffice. Note that since no LNet kernel resources are associated with end point objects, this issue is simply related to search performance.
References
For documentation links, please refer to this file : doc/motr-design-doc-list.rst
- HLD of Motr LNet Transport
- RPC Bulk Transfer Task Plan
- LNet Buffer Event Circular Queue DLD
- LNet Transport Kernel Core DLD
- LNet Transport User Space Core DLD
- LNet Transport Device DLD
